
이 포스팅은 도서 트랜스포머를 활용한 자연어 처리에 대한 리뷰를 담고 있습니다.

ChatGPT
인류의 역사에서 ChatGPT가 어떻게 기록될진 모르겠지만, 이것이 알파고 이후 AI가 일반 대중에게 의미있게 다가온 첫 사례라 생각한다. 그간 빅데이터, 알파고, 그리고 자율주행 등 AI 관련한 다양한 키워드가 유행했지만 그러한 키워드는 ChatGPT에 비하면 그저 흘러가는 유행어 정도일 것이다. ChatGPT는 GPT-3 를 기반으로 만든 서비스이고 현재는 GPT-4도 활용하고 있다. 이러한 GPT-X 시리즈는 Generative Pre-trained Transformer (GPT) 를 기반으로 한다.
언젠가 Transformer를 공부해야겠다 라는 생각을 하고 있었는데 트랜스포머를 활용한 자연어 처리 책을 읽으며 기본 동작 및 활용까지 잘 이해할 수 있었다. 석사 시절 NLP 분야 중 감성 분석을 전공했는데 그 시절 어렴풋이 이런 것이 되면 성능이 잘 나오지 않을까 상상하던 것이 있는데 임베딩 스페이스와 어텐션이 그와 유사하다는 것을 알게되었다. 몇 년 전 이직한 이후 Machine Learning (ML) 보단 서비스 개발 위주로 일을 하다보니 ML과 떨어져 지냈는데 트랜스포머를 활용한 자연어 처리 책을 읽으며 Attention이 무엇인지 그리고 Transformer가 어떻게 동작하는지 개념을 잡을 수 있었다.
Transformer
어느날 트랜스포머를 봐야겠다는 생각이 들어 논문을 펼쳐보니 이게 무슨 말인지 이해하기 참 어려웠다. 인터넷에서 트랜스포머를 설명하는 여러가지 자료도 찾아봤으나 잘 와닿지 않았다. 그러다 트랜스포머를 활용한 자연어 처리 책을 접할 기회가 생겨 살펴보니 점진적으로 설명을 잘 해주어 이해가 잘 되었다.
이 책은 트랜스포머가 무엇인지 간략한 소개 후 바로 그 개념을 설명한다. 그 후 개체명 인식, 텍스트 생성, 요약, 그리고 질문 답변이라는 NLP 연구 주제별로 활용 용도를 설명한다. ML 모델이 클수록 모델 효율화 및 데이터셋 구축이 모델링 작업보다 훨씬 더 많은 시간을 쓸 수 밖에 없는데 이에 대해 설명하며 책을 마무리하고 있다. 아래에서 이 책에 대한 내용을 간략히 정리해보았다.
트랜스포머에 대한 이해
1장과 2장을 통해 허깅페이스🤗에 대한 소개와 트랜스포머에 대한 소개를 한다.
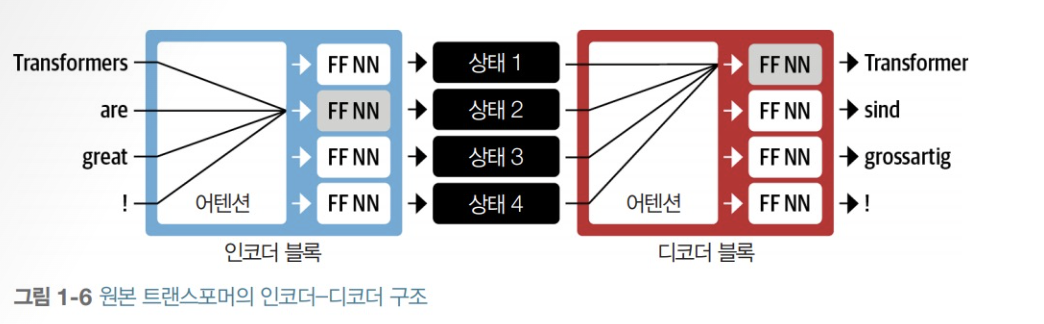
간단한 텍스트 분류 모델도 만드는데 아래와 같이 필요한 부분을 수정하여 DistilBERT 와 같은 모델을 미세튜닝 할 수 있다.
from transformers import Trainer
trainer = Trainer(model=model, args=training_args,
compute_metrics=compute_metrics,
train_dataset=emotions_encoded["train"],
eval_dataset=emotions_encoded["validation"],
tokenizer=tokenizer)
trainer.train()
석사 주제가 감성 분류였기에 이 예제가 더 와닿았는데 그 시절 뜨거운 감자였던 모델인 Latent Dirichlet Allocation (LDA)를 활용한 방법이 주류였다. 그러나 해당 모델은 embedding space가 아닌 확률 공간에서의 분포이기 때문에 그 자체가 의미를 갖고 있진 않아 그 모델 자체의 한계가 있다.
임베딩 공간을 기반으로 하여 트랜스포머를 통해 모델링한 결과를 보니 지난 10년간 ML 분야가 정말 많이 발전했다고 느껴진다. 이걸 따라가기 위해 논문을 하나하나 다 읽어보는 방법도 있겠지만 연구직 혹은 교수가 아닌 이상 현실적으로 어렵다. 이 책은 ML을 해본 분들이 최신 GPT의 기반을 이해하고자 할 때 큰 도움이 되는 책이라 생각한다.
기존에 ML 하시던 분들이 NLP가 어떻게 흘러가고 있는지와 트랜스포머를 이해하고자 할 때 정말 좋은 책이라 생각한다. word2vec이 출현하던 시기의 임베딩 공간을 이해하는 분들이라면 이 책의 내용을 이해하실 수 있을 것이다.
이 모델을 통해 할 수 있는 작업
트랜스포머는 기계어 번역을 위해 End-to-End로 Sequence-to-Sequence를 모델링 할 수 있다.
여기서 발전한 유명한 모델이 크게 2가지 있는데 GPT와 BERT이다.
재밌는 점은 Transformer의 변형 모델을 기반으로 아래의 문제를 풀었을 때 사람 수준으로 잘하기 시작했다는 것이다.
레이 커즈와일의 주장한 특이점이 온다에 한걸음 다가간 느낌이다.
이 책에서는 아래의 4가지 문제에 대해 어떻게 할 수 있는지 설명하고 있다.
개체명 인식 (Named Entity Recognition)
개체명 인식을 간단히 설명하자면 사람 이름, 지명, 혹은 날짜 등 문서/문장에서 나타나는 개체를 인식하는 작업이다. 아래와 같이 날짜 혹은 국가 등 개체를 인식하는 작업이다.

이는 문서 정재 작업에서 반드시 필요한 작업인데 석사 재학 중엔 ETRI의 NLP 모듈을 사용했다. 이 책에서는 허깅페이스의 라이브러리를 바탕으로 NER 모델링 방법을 설명해주는데 예제가 정말 간결하며 이정도라면 데이터가 있다고 가정했을 때, 직접 구축해서 사용해도 되겠다는 생각이 들 정도이다. 다국어 데이터셋을 통해 한번에 학습이 가능하기 때문이다.
텍스트 생성 (Text Generation)
텍스트 생성의 경우 우리가 잘아는 ChatGPT에서 풀어낸 문제이다. Copilot을 베타 때 사용하면서도 놀랍다 싶었는데 ChatGPT를 사용해보고 충격을 먹은터라 이젠 정말 Transformer를 이해해야 할 때가 왔다고 생각했다. 이 책을 접하게 된 이유도 그런 이유이다. 텍스트 생성의 경우 Sequence Generation인데 이를 어떻게 자연스럽게 할 수 있는지에 대한 다양한 방법을 설명하고 있다. 기본적인 방법론은 ML을 해본 분들이라면 보는 순간 이해할 수 있을 것이다. 다만 이런 방법들을 일일이 논문을 찾아가며 확인하려면 필요한 시간이 만만치 않기에 무엇이 있는지 전반적으로 이해하기에 아주 좋은 책이다.
요약 (Text Summarization)
요약의 경우 문서 요약 혹은 검색 결과 snippet 생성을 위해 함께 일하던 동료가 연구하던 것을 본적이 있다. 10년전엔 Text Rank 등 문서 내 중요한 키워드 혹은 문장을 추출하기 위해 노력했는데 트랜스포머는 모델이 한번에 읽을 수 있는 양을 통째로 분석해버린다. Context 보다 긴 텍스트의 경우 Attention도 함께 계산할 수 없기에 문서가 분절되어 입력이 되는 문제는 지금도 어려운 부분이라고 나와있지만 그럼에도 그 품질이 10년전에 비해 월등히 나아졌다고 느껴진다. 이 책에서는 요약 작업을 위해 발전한 모델의 계보와 어떻게 평가할 수 있고 모델을 구축할 수 있는지 설명하고 있다.
질문 답변 (Question & Answering)
우리가 구글을 사용하는 이유는 원하는 정보를 찾기 위해서이다.
예를 들면 마리 퀴리가 언제 처음으로 노밸상을 수상했나요? 와 같은 질문의 답을 얻기 위해서 말이다.
구글과 ChatGPT에 물어보면 각각 아래처럼 결과가 나온다.
-
Google
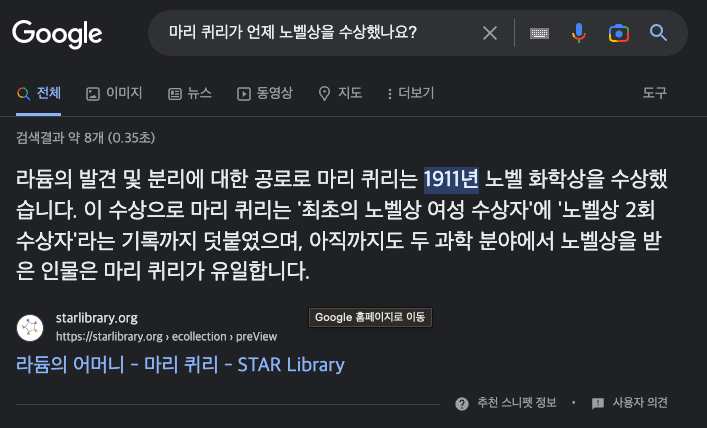
-
ChatGPT

이 책에서는 SQuAD와 SubjQA 모델과 이를 학습시키기 위한 데이터셋 그리고 평가 방법을 설명한다. QA 문제의 경우 직접 풀어볼 기회가 없었지만 이 책을 따라서 구축하면 baseline은 쉽게 만들 수 있을 것 같다.
효율화
Transformer를 학습시키기 위해 100억원 단위의 GPU 클러스터 구축은 예삿일이 되어가는 상황이다. 이 말인 즉슨 모델의 효율성을 조금이라도 증가시키면 GPU 클러스터 구축 비용이 줄거나 학습 시간이 줄어든다는 이야기다. 결국 리소스가 절약된다.
이 책에선 이를 위한 방법 4가지를 소개하고 있다.
- 지식 정제 (Knowledge Distillation)
- 양자화 (Quantization)
- 가지치기 (Pruning)
- 그래프 최적화 (Graph Optimization)
이 중 양자화는 들어보긴 했는데 이 책을 통해 기본 개념이 무엇인지 올바르게 이해할 수 있었다. 효율화는 ML 모델링 영역이 아닌 DevOps의 영역이라고도 할 수 있겠다. 상황이 이렇다보니 최근에 MLOps라는 용어도 나왔지만 DevOps를 깊게 해본 사람일 수록 자원의 효율화를 잘할 수 있는 것 아닌가라는 의견이다.
데이터 구축
이 책의 후반부엔 레이블 부족 문제와 대규모 데이터 구축에 대해 설명한다. word2vec이 처음 나와 이해할 때도 그랬었지만 레이블 없는 데이터에서 학습할 수 있는 모델을 설계하는 것이 상당히 중요하다.
레이블 데이터의 유무와 있을 경우 그 비중이 어라나 되는지에 따라 여러 발전방향이 있는데 이 책에는 각 상황별 방법론에 대한 설명이 잘 나와있다. 예를 들어 제로샷 학습의 경우 레이블링된 데이터가 없을 때 사용할 수 있는 방법이다.
또한 대규모 데이터가 있을 때 생길 수 있는 문제점과 여러개의 GPU를 사용하여 학습하는 방법에 대해 설명하고 있다. 앞선 단락에서 이야기 했던 DevOps/MLOps가 이러한 분산 시스템을 설계/분석/운용하는 역할을 맡게 된다. GPU가 본격적으로 쓰이기 전 CPU 수십만개로 학습하던 과정 그리고 최근에는 GPU를 수만개 이상 운용하는 경험은 IT를 이끌고 있는 기업 외엔 경험하기 어려울 것이다. 이 책에서는 여러개의 GPU 운용을 위한 기초를 설명하고 있다. 만약 대규모 클러스터를 운용하고자 하는 분들이 계시다면 이 책의 기초를 이해한 후 점진적으로 키워가며 이슈를 대응하면 하면 될 것이다.
마무리
이 책의 소개글은 꽤나 인상적이다. ChatGPT의 기반 기술인 트랜스포머를 다룬다는 것을 짧고 명확하게 설명하고 있다.

책을 다 읽고 난 이후 트랜스포머에 여러 발 가까워진 느낌이다. 이 책의 예제 중 실제로 풀어보면 좋을 문제를 하나 선정해 진행해 볼 예정이다. 여유가 된다면 해당 내용도 포스팅으로 정리하도록 하겠다.
아래에는 한빛미디어에서 나온 ML 책 중 같이 보기 좋은 책을 몇 권 추려보았다. 이 책을 관심있게 보실 분들이라면 필요성이 있어서일텐데 다른 책에선 어떤 이야기를 하는지 한번 살펴보는 것도 좋을 것이다.
같이 보면 좋은 책



한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.